Forecasting breast cancer can significantly increase the survival rate of patients, and classifying the sample tumor cells as malignant or benign is one of the best and most direct ways to make accurate predictions. Breast Cancer Wisconsin from UCI Machine Learning Repository was chosen as the dataset to implement machine models and predict diagnosis result on practical cases. The target variable in this dataset is the final diagnosis whether the tumor is malignant or benign. There are 30 real-valued columns as independent variables with three properties, mean, standard error and worst cases, for 10 cytological features.
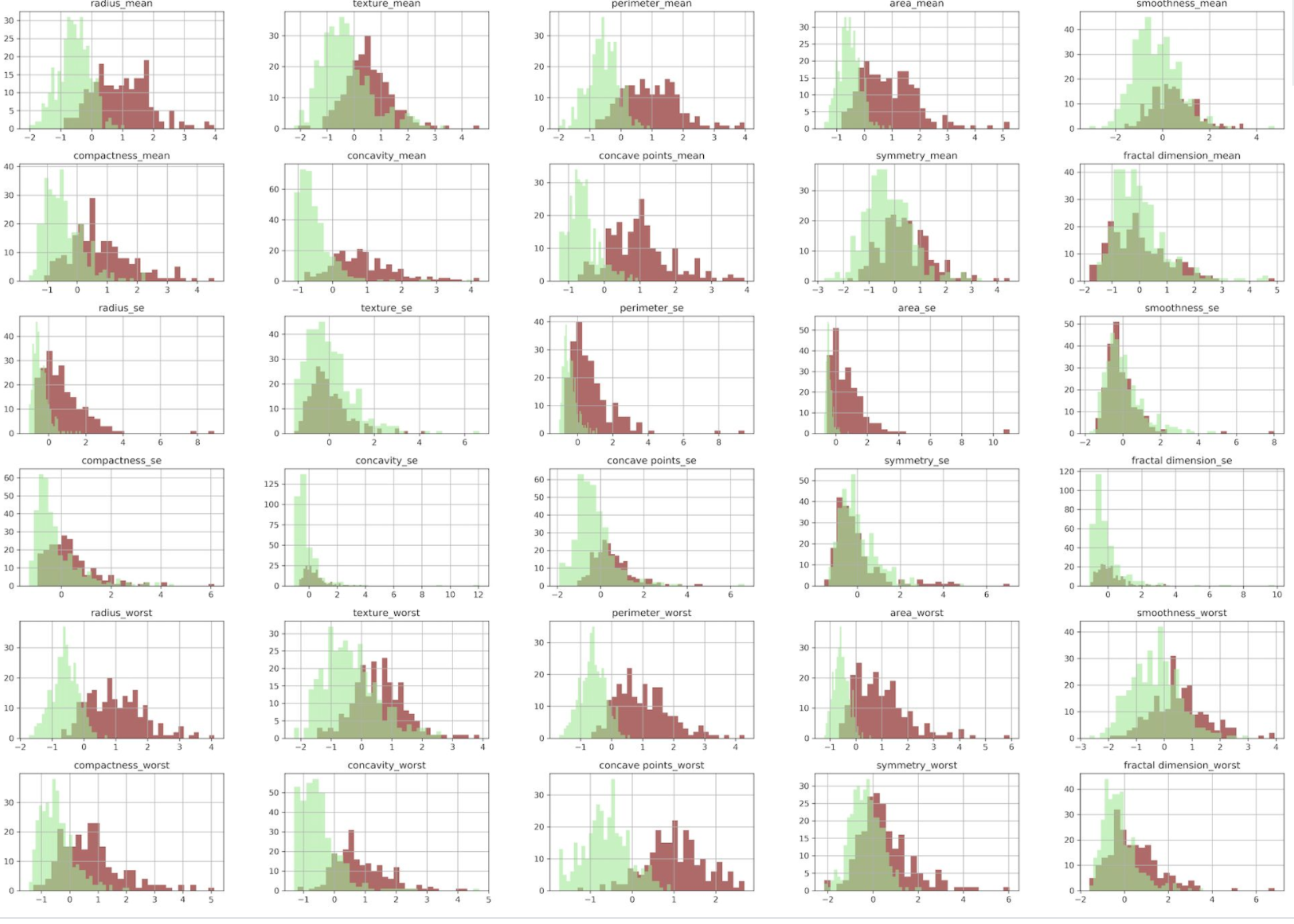
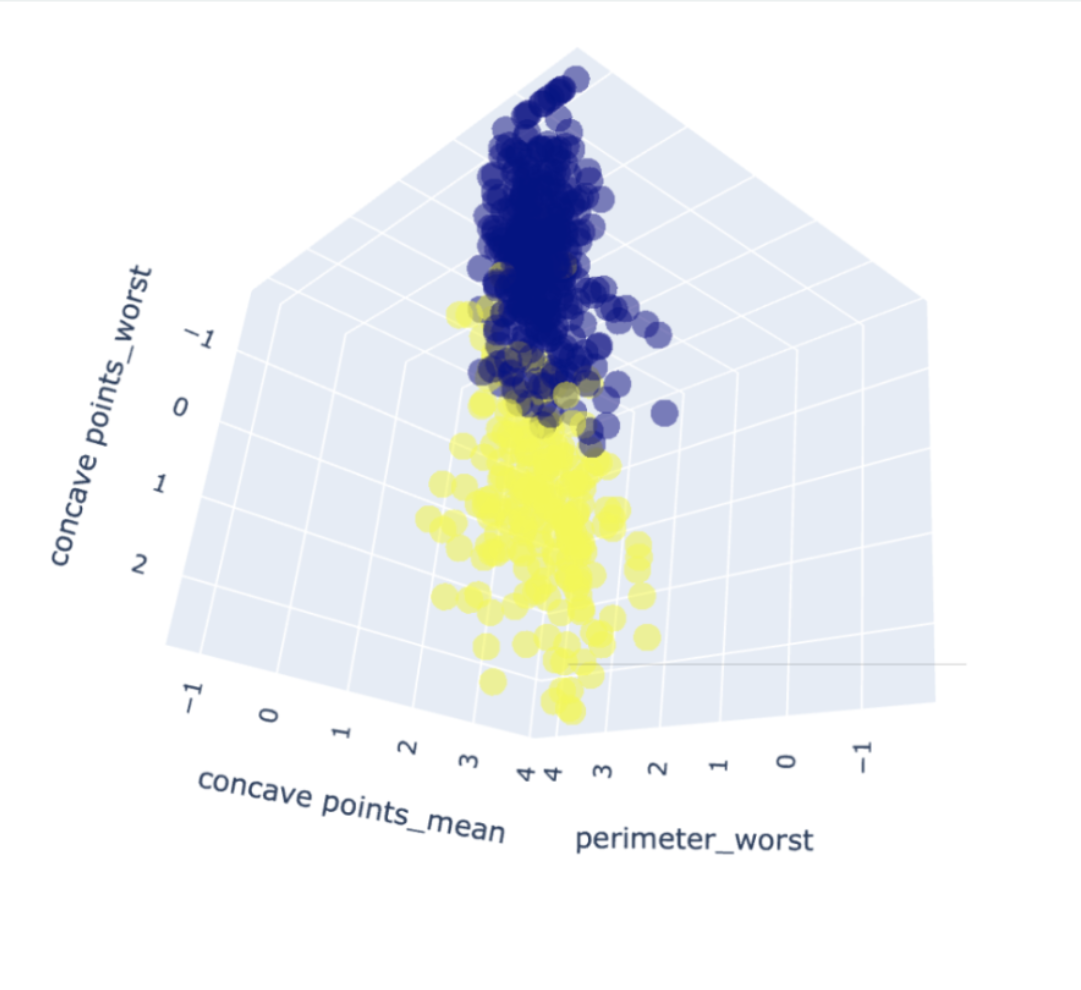
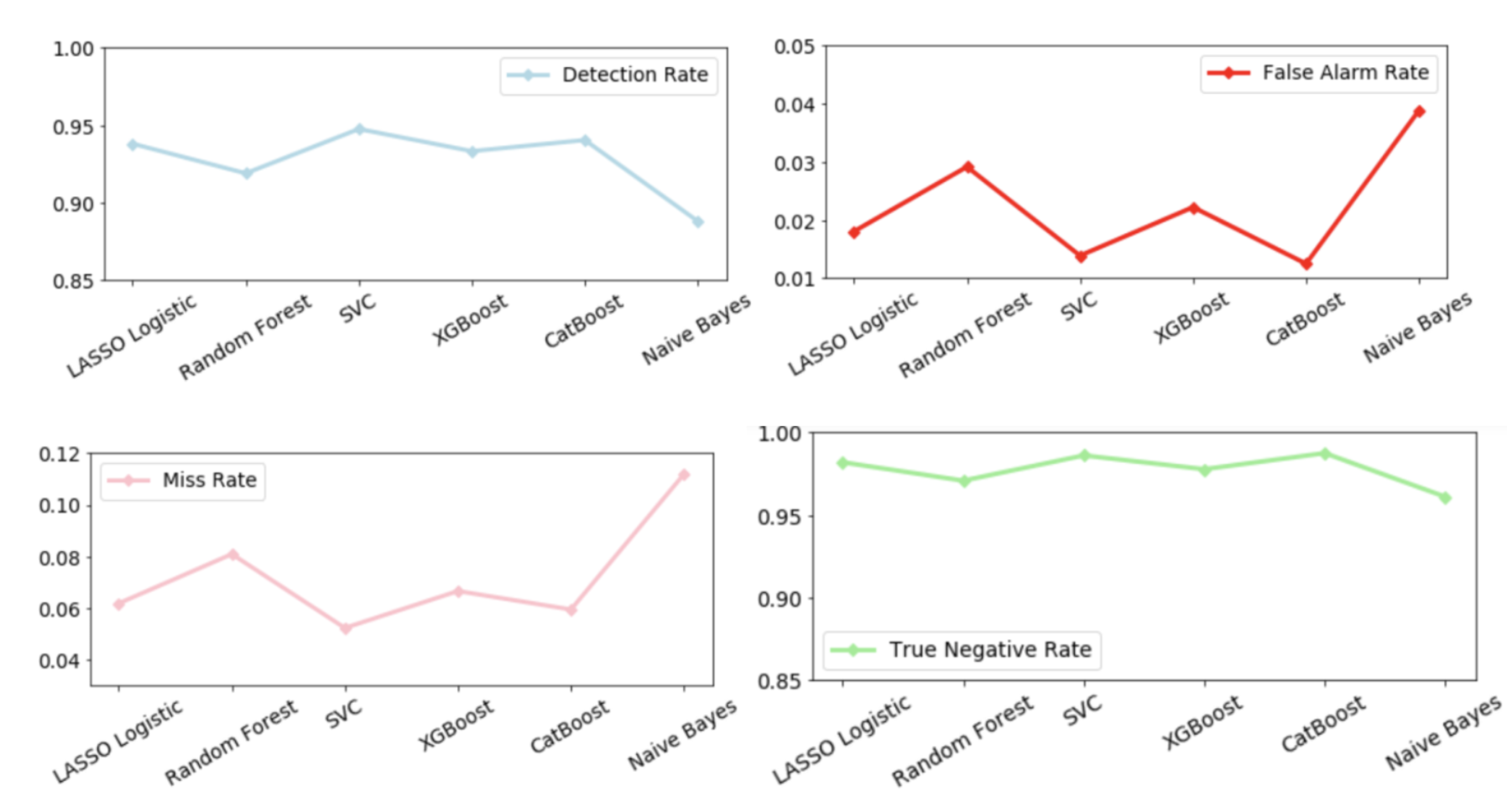
Explotatry data analysis(EDA) was first conducted to explore both independent variables and target variables. For example, the above two figures show that some cytological features are more predictive than other features on diagnosis result. For machine learning algorithms, LASSO regression, support vector machine, random forest, gradient boosting and Gaussian naive bayes classifier, were applied to this classification problem. In addition to the prediction accuracy, confusion matrix was then analyzed for the purpose of reducing Type II error. This is becasue clinical trials do not want to classify any positive cases as negative cases, resulting in delaying the treatments.
To view my final report, follow this link to download. My code and models can be found in my Github Repository.