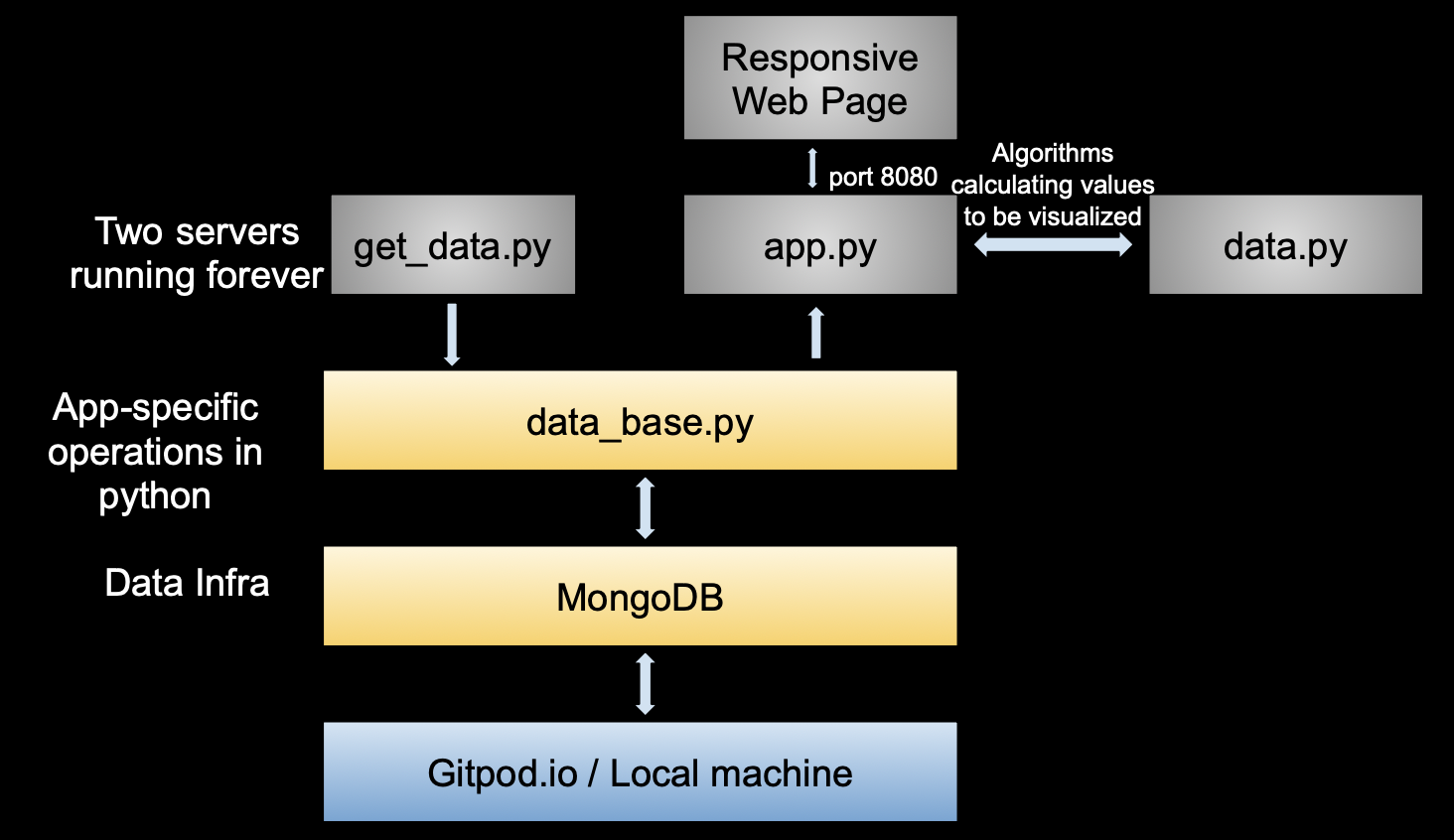
In this data science project, an entire data engineering pipeline was built from scratch: Obtaining raw data from the website, storing data inside the database (MongoDB), retrieving and processing data from the database and visualizing data based on users’ queries. Specifically, the data we are using is dynamic and it is constantly acquired from the web. We then renew such data into the MongoDB database, making the updated data ready to be renewed. Once a new query is input through the dash user interface, our program is able to retrieve the data from the database, calculate the values we need and utilize such data to conduct data visualization. These values are also utilized for calculating the result of virtual matches. The figure below shows the architecture design of our data engineering pipeline.
 Please take a look at our final screencast here (or below) demonstrating the usage of user interface and how this pipeline was designed. The source code can be found at this repository. You can fork it to your own git repository and run it on gitpod or your local environment. The server will be able to automatically start.
Please take a look at our final screencast here (or below) demonstrating the usage of user interface and how this pipeline was designed. The source code can be found at this repository. You can fork it to your own git repository and run it on gitpod or your local environment. The server will be able to automatically start.