Bengali is the 5th most spoken language in the world with hundreds of millions of speakers. Considering this, there’s a significant business and educational interest in developing AI that can optically recognize images of the language handwritten. In this project, we used trasfer leanring based CNN to classify the three constituents of Bengali Graphemes, grapheme roots, vowel diacritic and consonant diacritic.
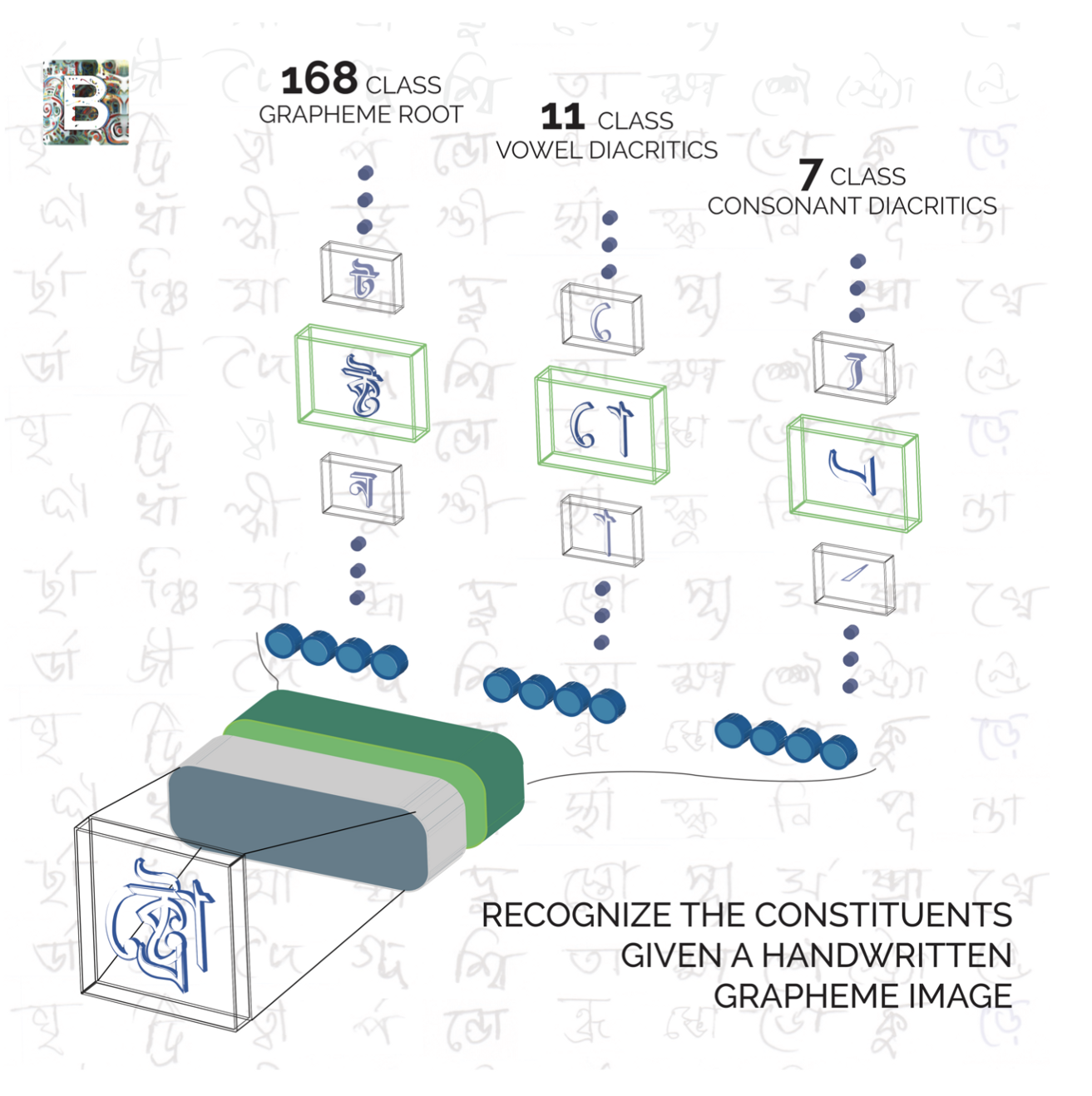
As shown above, there are 168 types of consonant diacritic roots, 11 types of vowel diacritics, and 7 types of consonant diacritics, a total of 186 classes. For the neural network architecture, we built convolutional neural network and used ResNet. By implementing data augmentation, image resizing and parameter tuning, we achieved classification accuracy of 96%, 99% and 99% for the three consitituents, and an overall accuracy of 95% (correctly classifying all three constituents). We also implemented bagging strategy to use the mode value of predicitons from different models as our final prediction. This further increased the overall accuracy very close to 96%.
Please check out our final post here. Our video demonstration can be viewed here or played below.